Problem:
In order to understand the likelihood of success, the user wants to know how effective the algorithm is before initiating an operation.
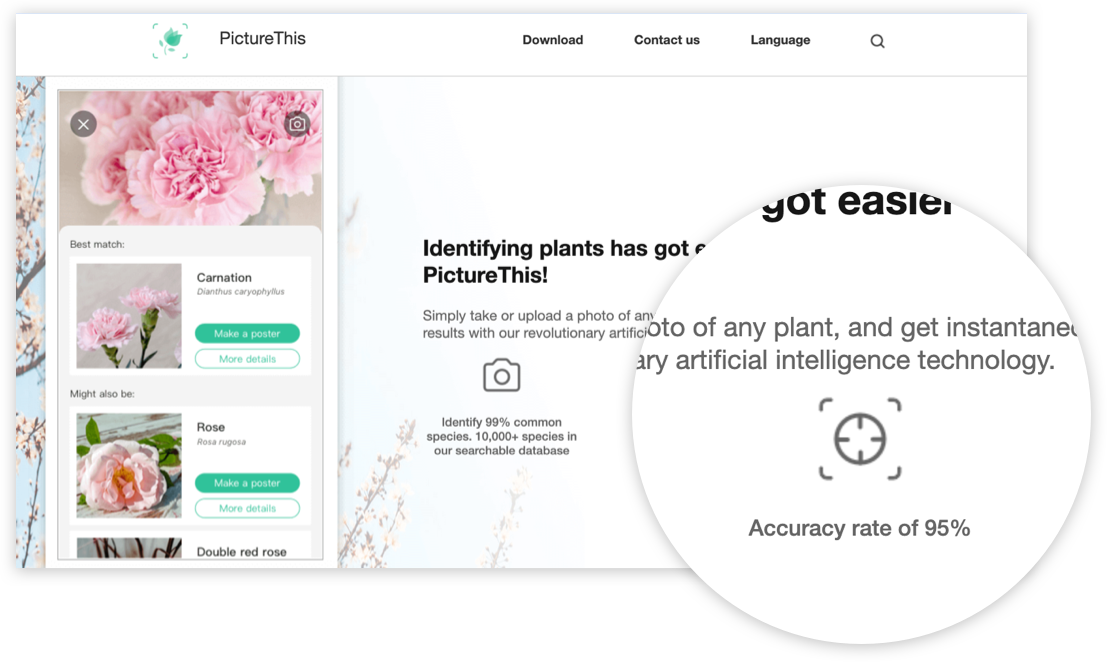
Solution:
The system communicates an effectiveness metric. For example, in pattern recognition operations this could be indicated in terms of what percentage of image capture inputs result in a successful match with the correct data points.
Discussion:
Obviously if a system communicates that it is less than 100% successful 100% of the time, that can undermine the confidence a user has in that system. But in the the long term, acknowledging the fallibility of a system is a vital part of building trust in it (as per Setting Expectations and Acknowledging Limits).
Quantifying the effectiveness with a score provides a couple of advantages over a vaguer, copy-driven approach. Firstly, if the metric is comparable to ones used by similar competitor systems, the user can easily establish how this system compares to others. Secondly, as the score is subject to change, this allows the system to track and communicate how it has improved over time — acknowledging initial shortcomings while establishing a trajectory towards increased success encourages the user to return later and engage further, as opposed to simply overpromising and underdelivering on first use, which can discourage further exploration.