Problem:
The user does not want to be misgendered by an AI. In fact, the user does not want a piece of software to make any assumptions about their gender at all.
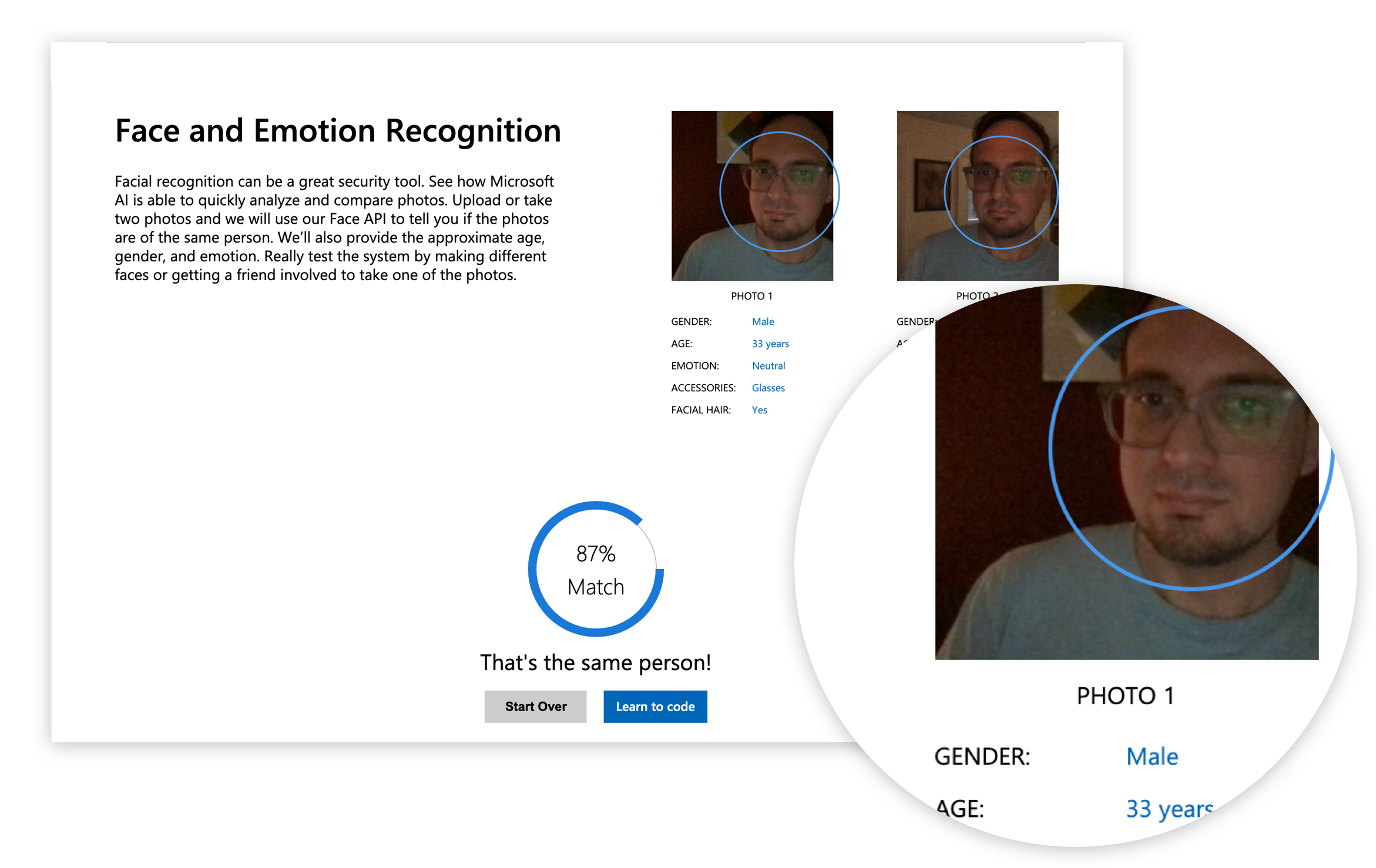
Anti-pattern response:
An image recognition AI attributes data points to an image of the user, one of which is the user’s gender. Variants of this include AI-powered systems attempting the same prediction via speech recognition, textual analysis, behaviour tracking, and so on.
Discussion:
By using data pulled from a collection of individuals, we train AI systems to make predictions about any one individual based on what it learns about the group. In some cases, these generalizations and assumptions will be accurate and useful. In other cases, there are faults in the dataset that can cause problems, either due to biases in the sample data or faulty extrapolation from that data. When the data points concern superfluous details such as whether the user wears glasses or not, that user will not be offended by incorrect data attached to them. When the data concerns matters of gender identity, sexual orientation, racial or cultural identity, or other matters that the user is deeply affected by, much greater care should be taken about generating accurate assumptions.
In the case of gender, there are two substantial problems to overcome initially. First, a male/female binary is incorrect and simply adding more options (non-binary, for example) will likely also be an inadequate simplification. Second, assuming we could create a satisfactory catalogue of gender positions, the challenge would be to ensure the dataset captured contains a sampling of enough diversity to be predictively useful. Ultimately though, this functionality is doomed to fail simply because many individuals’ gender presentation doesn’t match their actual gender. If a system deploys this pattern, it will inevitably be inaccurate and cause offence for a number of users.
This pattern is indicative of a core challenge in developing AI functionality. Given that almost everything will prove possible to build in due course, the question is not whether we can build it, but whether we should. In this case, whatever benefits there may be must be weighed against the fact that the harm caused is impossible to mitigate.
A second core challenge is that when we are concerned with capturing and generating data without a deeper understanding of the nature of that data, we are always in danger of not just replicating existing harmful biases, but amplifying them and solidifying them.